Convert PDF to JSON – How to Turn PDF Documents into Structured Data
Convert PDF to JSON with FormX to turn unstructured documents to structured data. It only takes 4 steps for you to start automati

PDFs have undoubtedly become the default exchange format for business documents, but the way data is stored in them often limits their usability. We’re going to dig into exactly why that is, how converting your PDFs to JSON can transform the way your business manages its data, and the tools you need to do it all.

PDFs are already considered an upgrade from paper documents, so why upgrade further? The reason is all in the data. PDFs are an unstructured document format and as such, the data they store is unstructured too. This makes it especially difficult to selectively extract specific data from PDFs for further processing and usage.
It’s become an increasingly tricky obstacle for businesses to have their data trapped in PDF documents, unable to extract it accurately without manual intervention. JavaScript Object Notation (JSON), on the other hand, provides an ideal format for storing and transmitting data in the form of attribute-value pairs and arrays. Although JSON does not have fancy layouts that many PDF files may have, it’s not only human-readable but more importantly can be read by machines. It’s why web applications rely on them so much and it has become one of the most common medium for exchanging text-based data.
Despite their challenges, PDFs are too useful to switch from completely and you cannot expect everyone, such as your business partners, suppliers, and more, to abandon PDF. The fix is then to set up a system whereby documents are automatically converted from PDF to JSON files so that the data trapped in the PDFs can be leveraged to automate business processes. That way, businesses can continue to use PDFs without being limited by them.
The problem with trying to convert PDF to JSON is that, depending on the complexity of the PDF layout and the types of data you’re trying to extract, it can be quite a challenging process. However, it’s a challenge that we’ve taken on at FormX and developed highly effective solutions for. Before we get there though, it’s important to understand what makes a PDF different from a JSON and how converting documents can alter the way we use them.

PDF and JSON each have their own purposes and advantages. Understanding when to shift from using one to the other starts with looking at how differently they each store data.
The main purpose of a PDF or “portable document format” is to preserve the layout of the document. This means that even with multiple pages and various pieces of text, objects, and images on them, people can open the files on any devices and operating systems and share them with the assurance that once opened, the layout will still be maintained.
The compatibility and reliability of PDFs are what have made them so useful in the business world. Unfortunately, all that data that they store is unstructured and PDFs can come with very different formats. It then becomes very difficult to extract the information. Because of this, the ideal data extraction solution that can extract data from multi-page PDFs must have the capability to learn and process images and files with different layouts. JSON files, on the other hand, are much easier to work with.
Instead of preserving layouts, the central purpose of a JSON is to store data in a manner that is suitable for both humans and computers to read. Often used in web applications, the information in a JSON file is stored in a set of key-value pairs (KVP) with the possible data types being:
- Number: A number that isn’t wrapped in double quotes.
- String: A set of characters wrapped in double quotes.
- Boolean: True or false.
- Array: A list of values that are wrapped in [closed brackets].
- Object: Key-value pairs wrapped in {braces}.
- Null: Represents no value.
The image shown below is a JSON result and illustrates what a receipt looks like when converted from PDF to JSON by FormX. You can see how the information extracted from the PDF is readable to both a human and a computer, making JSON perfect for manual editing as well as for automatic processing.
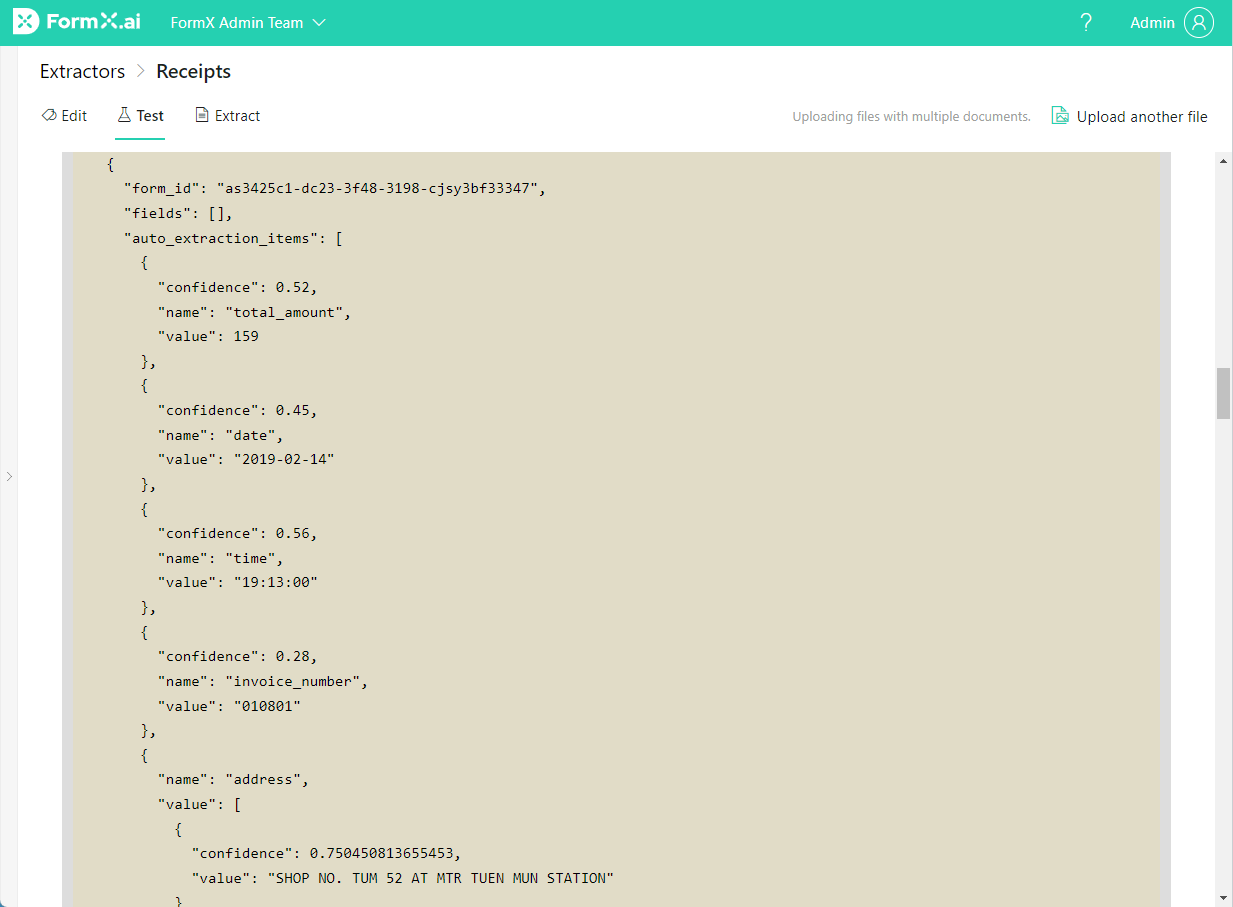
How a JSON file looks like in FormX
The best way to consider the difference between a PDF and a JSON file is that a PDF is about prioritizing the integrity of the layout while the purpose of a JSON is data storage and transmission. That’s why when it comes to speeding up your automated data processing, JSON files work so much better.

PDFs lack a hierarchical structure in elements, such as
and
in HTML for example. By converting them to JSON, this information becomes structured. A headline inside a PDF document is just considered to be “normal” text in a larger font size and a table is just a collection of text fields placed in certain positions inside the document. This is all to say that there is no relation between the elements preserved in a PDF file apart from the visual representation. The consequence of this is that software is then unable to “understand” the represented data. Moreover, PDF files come with different formats and may contain images that cannot be understood by machines without advanced technologies.
As such, to accurately extract information from a PDF with multiple images and pages, you need to identify data and context. It’s why converting a PDF to JSON can be quite a challenge. The way that it’s usually performed is through manual data entry, which may work fine when there’s only a small number of PDFs to process. Sadly, many businesses often have to process countless PDF files on a daily basis and it’s not a sustainable approach for businesses to deal with them manually.
What’s needed is software that can turn PDF information into structured data so that more can be done with it. A solution that many are implementing to speed up their PDF processing is Intelligent Document Processing solutions. This kind of software, combining OCR with AI and ML technology, can understand the context of a PDF as well as the data it it and convert it to a JSON where the information is then available in a structured, usable format.

Implementing Intelligent Document Processing (IDP) solution, and using it to convert PDF to JSON can transform several business processes:
Collecting and leveraging consumer data to know their preferences is essential to running a successful retail business; however, information like the date and time of the purchase, the total amount of products bought, names of the products, etc. is usually trapped in images or PDF files. With IDP solutions, those files can be converted from PDF to JSON and the data in them automatically extracted and fed into systems for further analysis.
Extracting data from PDFs with images of receipts using receipt OCR erases the manual labor that data entry would have otherwise required. It also means that retailers are better equipped to analyze consumer behaviors accurately, quickly, and more cost-effectively. With more and faster data, retail businesses can then make personalized recommendations and offers that will further help them grow product sales and build customer loyalty.
In addition, many retail businesses have developed loyalty apps where consumers can upload images of their receipts to accumulate points. With IDP solutions, these receipt images can be processed automatically, simplifying the process for consumers.
Telecom operators generally require users to upload images of their ID documents in PDF form when getting new phone numbers. With the boost of an OCR application or IDP, the software could import a customer’s information from those images to the company’s database in seconds. This saves both the salesperson’s time and makes for a far swifter and neater experience for the telecom customer.
Contact us to see how you can benefit from automating data extraction from PDF to JSON.
OCR provides similar benefits in the banking and insurance world. Thanks to the early adoption of automation software and OCR in the finance industry, we’ve been able to see just how much this technology can improve a business’s workflow. OCR has allowed banks and insurers to automate customer onboarding by capturing data from passports, IDs, and proof of address documents, thus creating a better customer experience overall.
Most of those documents tend to be submitted as scanned, PDF copies and would usually require a lot of time and effort to manually extract the necessary data. Software that can convert those PDFs to JSON makes that data available for automation and speeds up the entire process. It’s also been used to seriously improve the accuracy and efficiency of how data is extracted from other PDFs such as mortgage applications, bank statements, pay slips, business certificates, and loan applications.
FormX is a robust, reliable solution that helps businesses automate the data extraction process and extract more accurate insights from their PDF documents. Here are the steps for you to convert your PDF file to JSON with the help of FormX
Sign-up for FormX
Sign up for a free trial to start setting up your extractor to convert PDF or images to JSON.

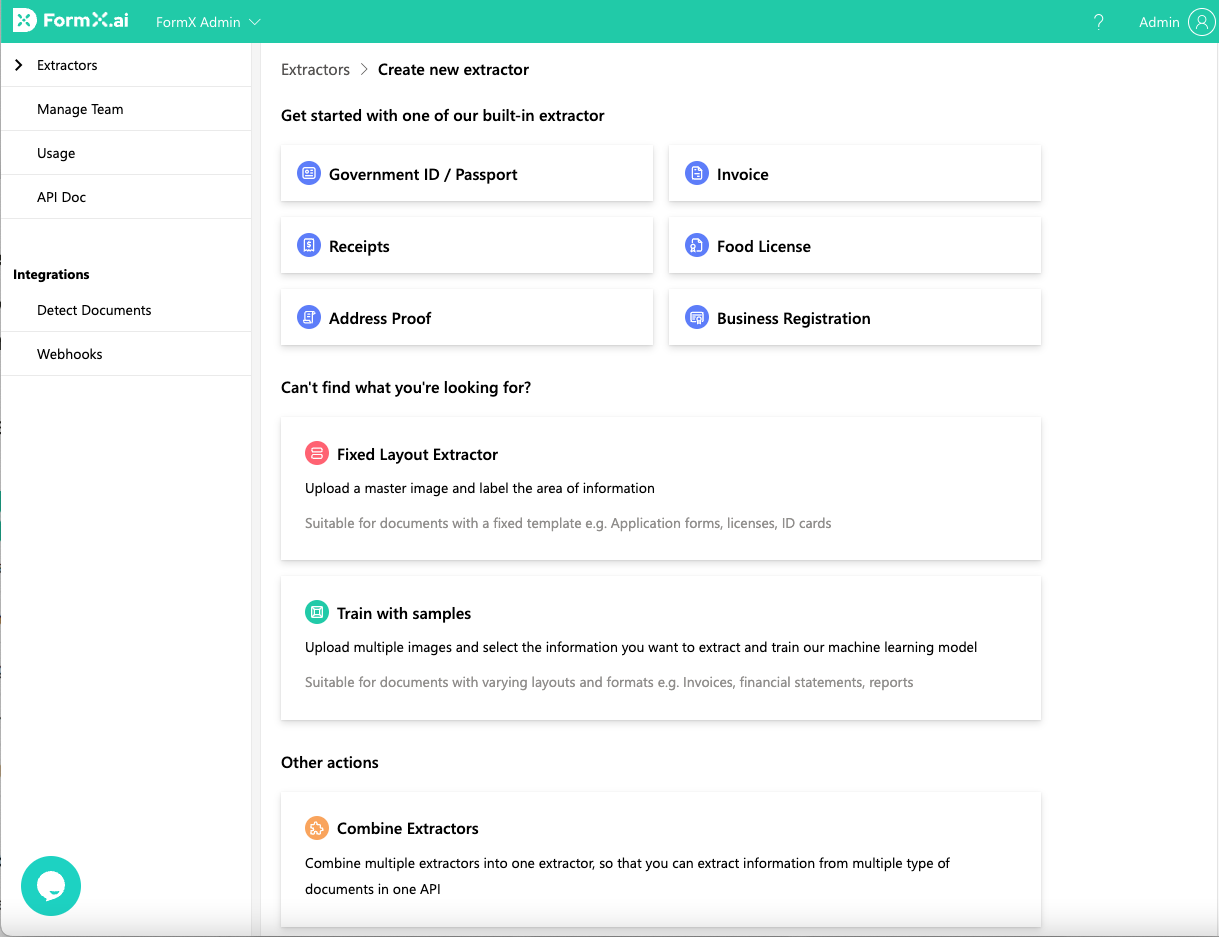
Create Your First Extractor
FormX has provided a set of pre-built extractors such as IDs, invoice, receipt, address proof, food license, and business registration. In addition, as our solution is powered by machine learning, you can also train your own extractor by uploading sample images and label the data fields that you wish to extract without writing a single line of code.
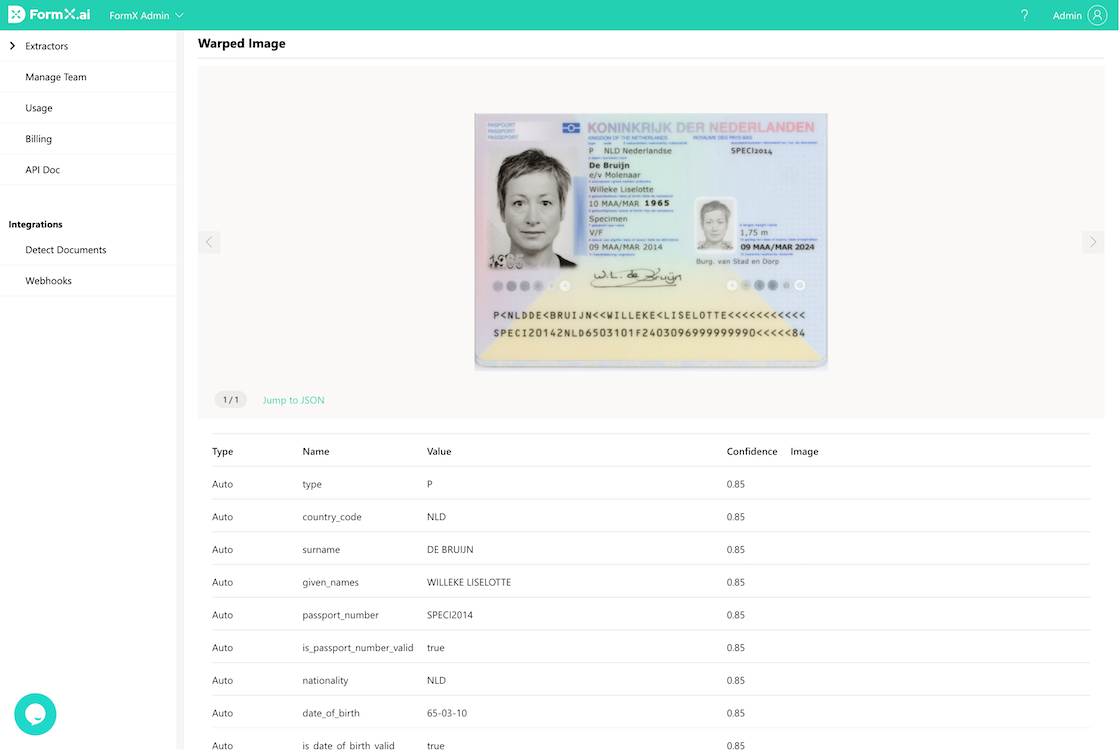
Test Your Extractor
After the extractors are set, you could upload PDF documents that you’d like to convert and check the results.
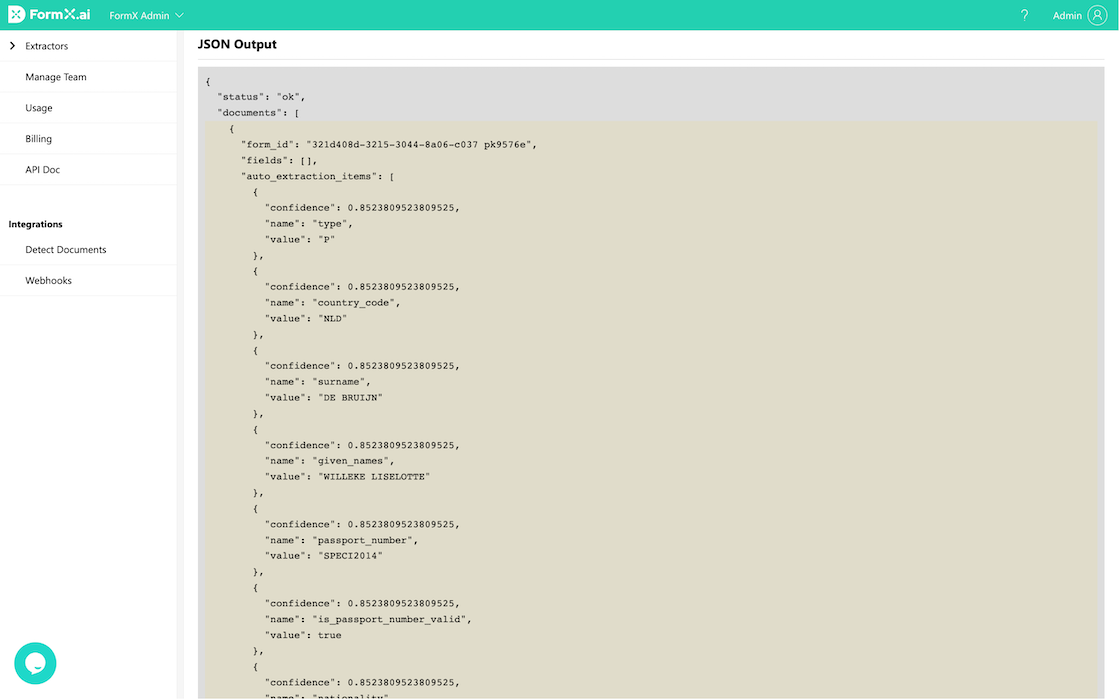
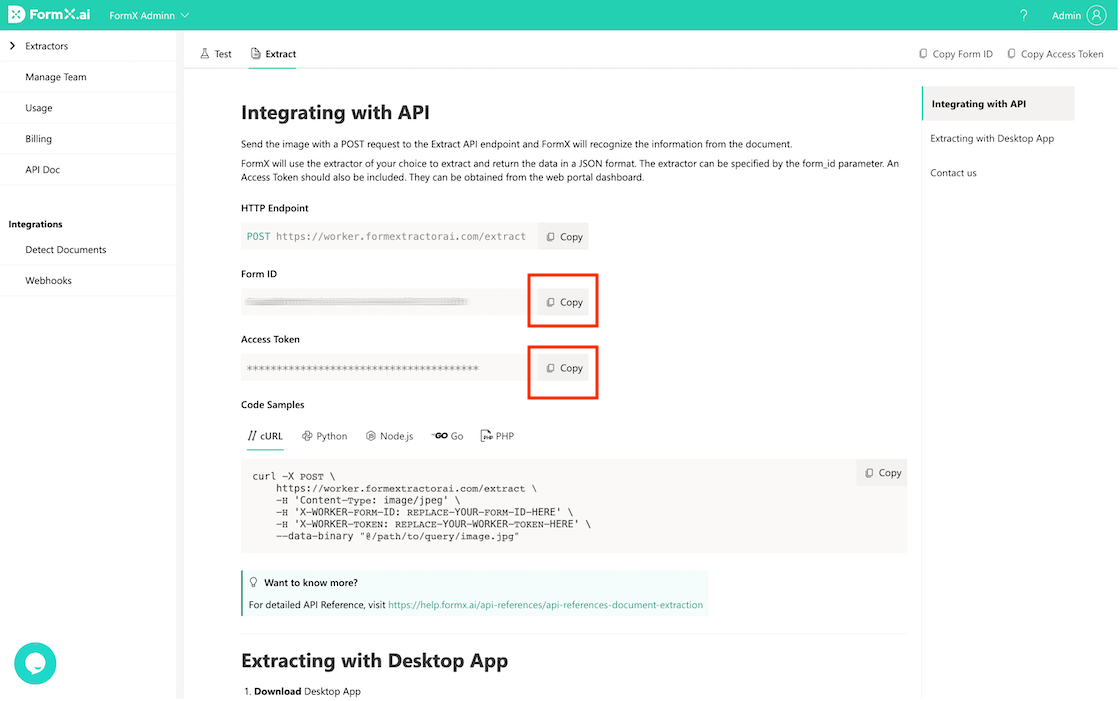
Obtain Form ID and Access Token
You could copy the Form ID and Access Token from the “Extract” tab. The ID and Token can be used to integrate FormX with your software to enrich the automation workflow.
The extractor can be integrated using the RESTful API and enrich the automation workflow. Send the image to the API endpoint “https://worker.formextractorai.com/extract” with the Form ID and Access Token. Then, in the API response, you will see the extracted information.
Ready to Convert?
Automation can bring major improvements to a business’s overall efficiency, the experience of their customers, and in turn, their profit margins. The obstacle that often stops this process from getting off the ground is how much data is stuck in unstructured PDF files. OCR software, alongside AI and ML technology, means that you can convert PDF to JSON and free that data for automation and analysis.
If you’re not sure how to automate converting PDF files to JSON format, contact us here to tell us more about your business needs and learn more about how FormX can help you.
Latest articles



