
New Extractor Now Needs As Little As Zero Sample to Train
Training a new data extraction model, or Extractor as we call it on FormX, used to require a certain number of sample images and some manual labelling to ensure maximum accuracy. This process is now significantly shortened with the recent advancement in AI technology. With FormX, you can now create your new Extractor with as little as ZERO sample image.
When creating a new Zero-Training Extractor, click on “Custom Model Extractor.”
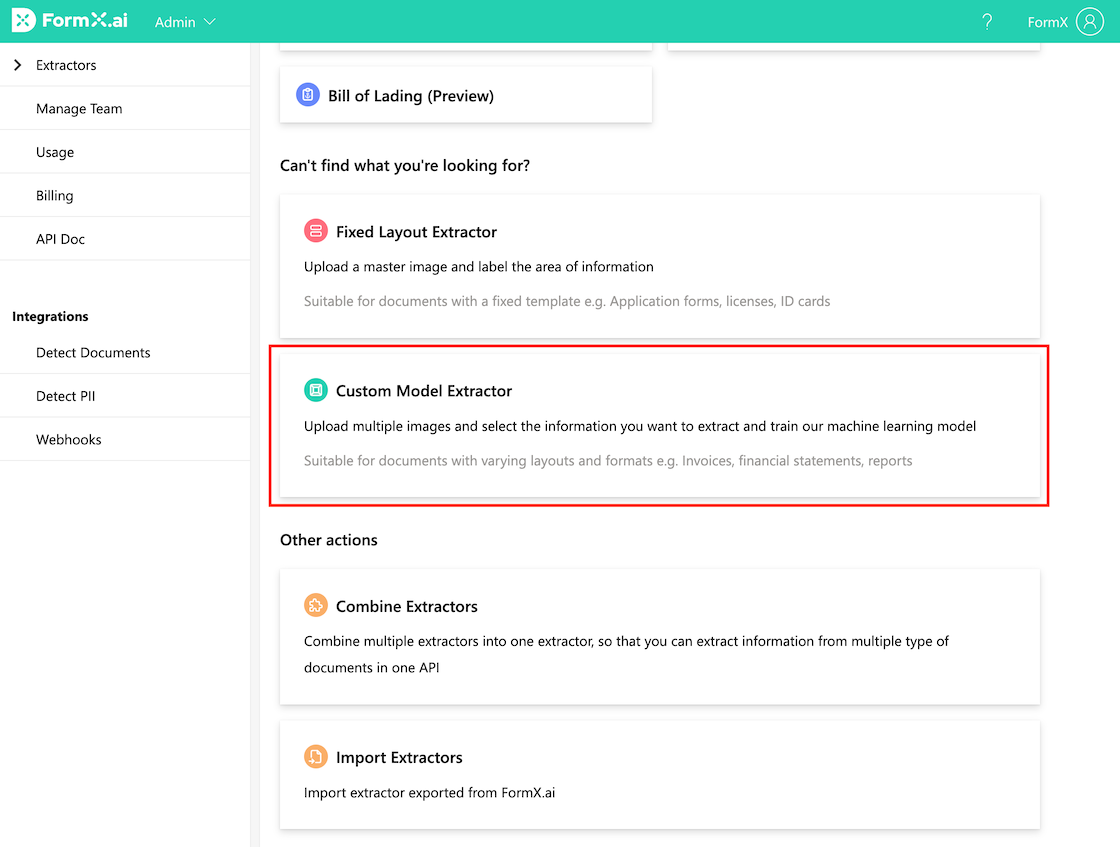
Afterwards, you can build your own Zero-Training Extractor from scratch. To get an idea of how to set up the data fields, click on one of the example Extractors to see how you should name the fields.
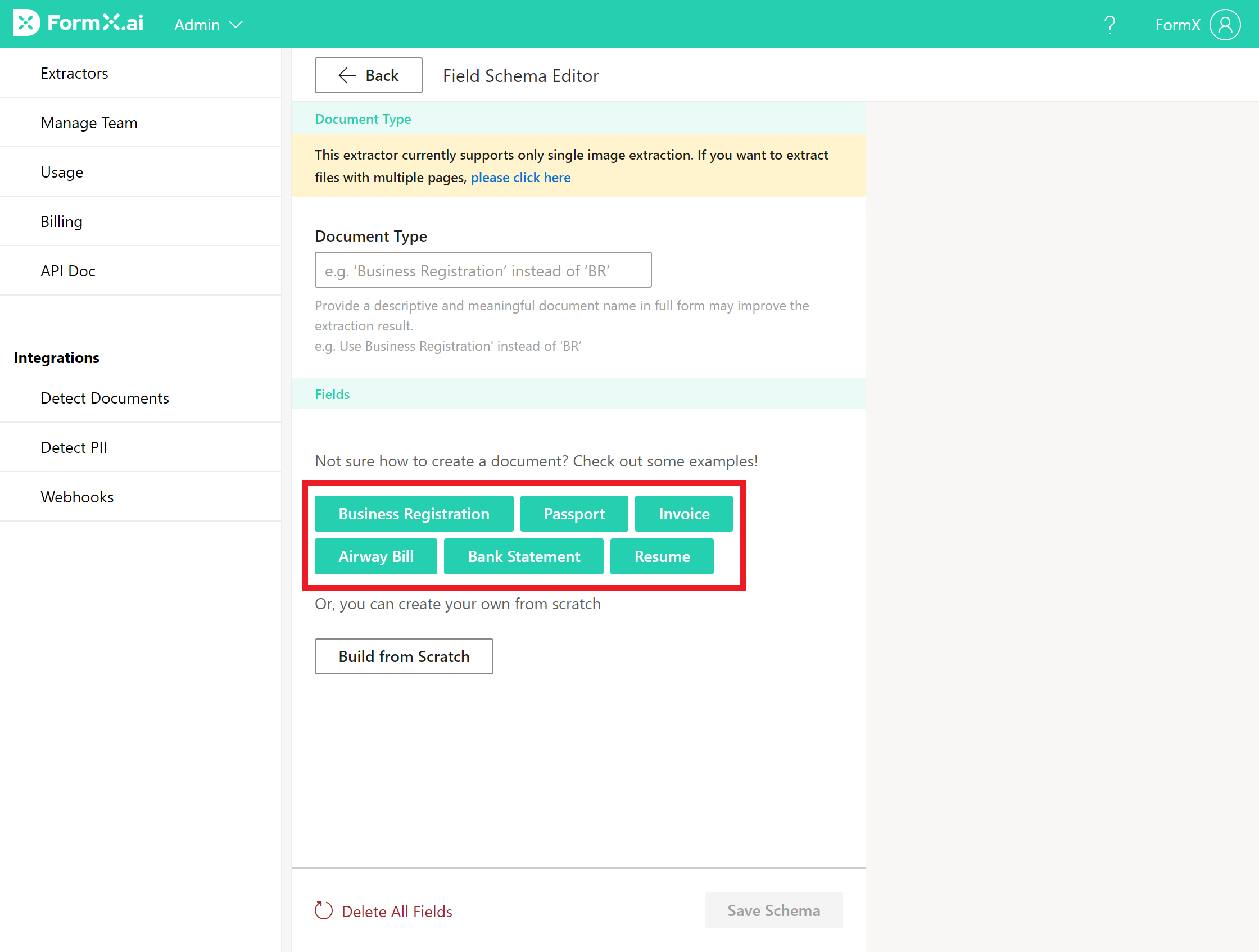
Build from Scratch
When building an Extractor from scratch, start by clicking on the “Add New Field” button to add the data fields that you want the Extractor to extract automatically.
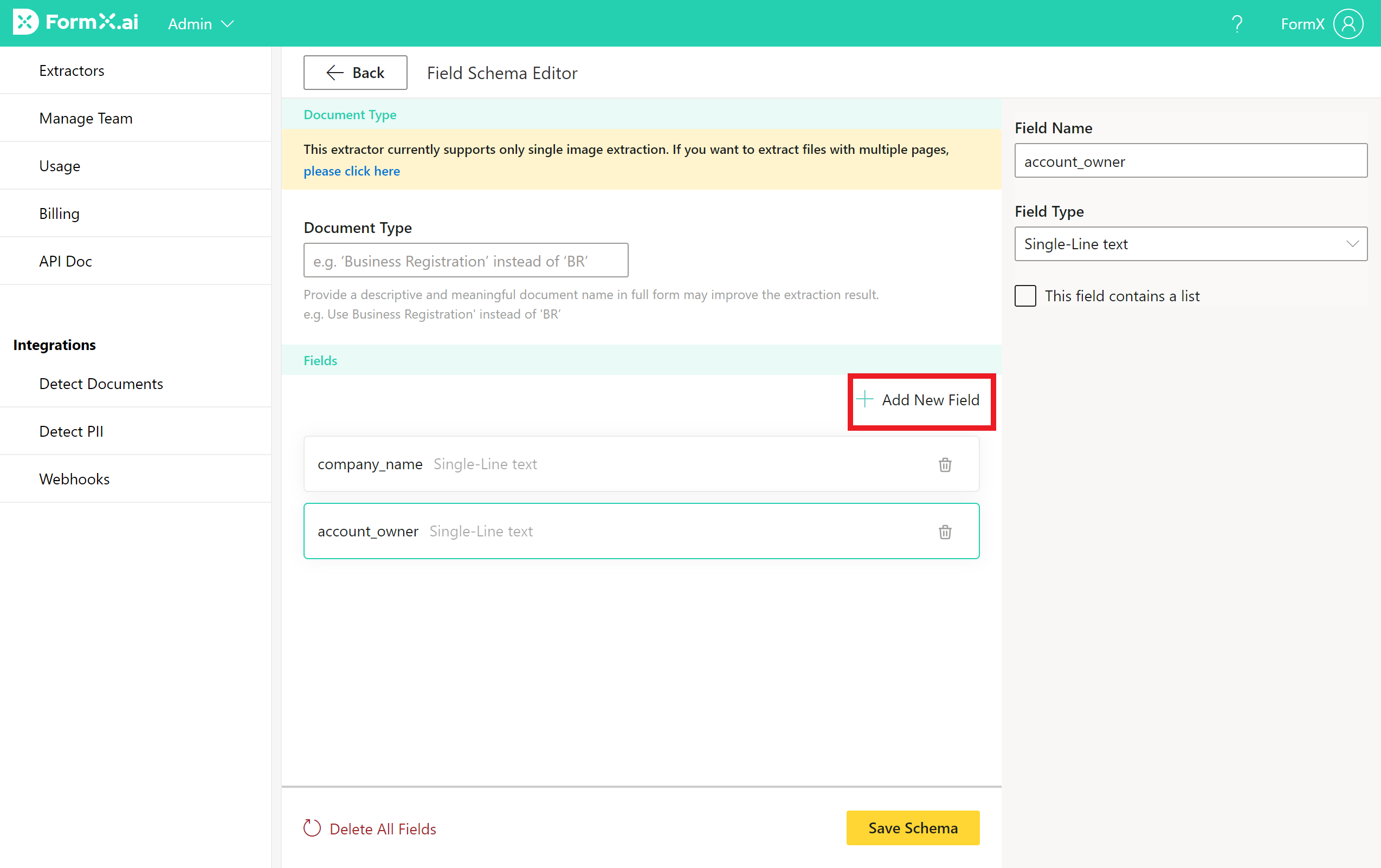
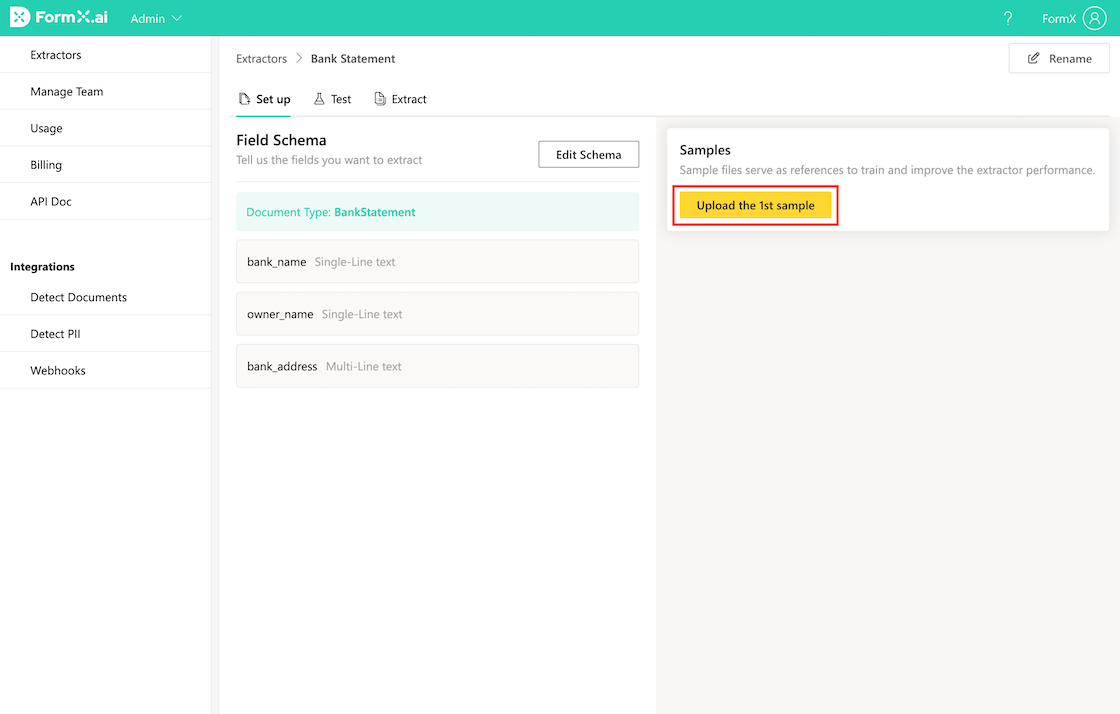
Enter the Field Name and select the proper Field Type as you create the fields on the right column. When you’re done, click on the “Save Schema” button. Afterwards, you can upload one to three sample images to maximize the extraction accuracy of your Extractor and begin testing and integrating your Extractor with other software or application.
Receipt Extractor Now Supports Digital Payment Receipts
Our pre-built Receipt Extractor now can not only extract data from digital receipts generated by Digital Payment platforms, such as Apple Pay, Google Pay, Alipay, WeChat Pay, and Payme, but also determine the type of receipt, whether it’s a paper receipt, receipt generated from digital wallets, or from other sources, and also which digital wallet it’s from and return them in the JSON result.
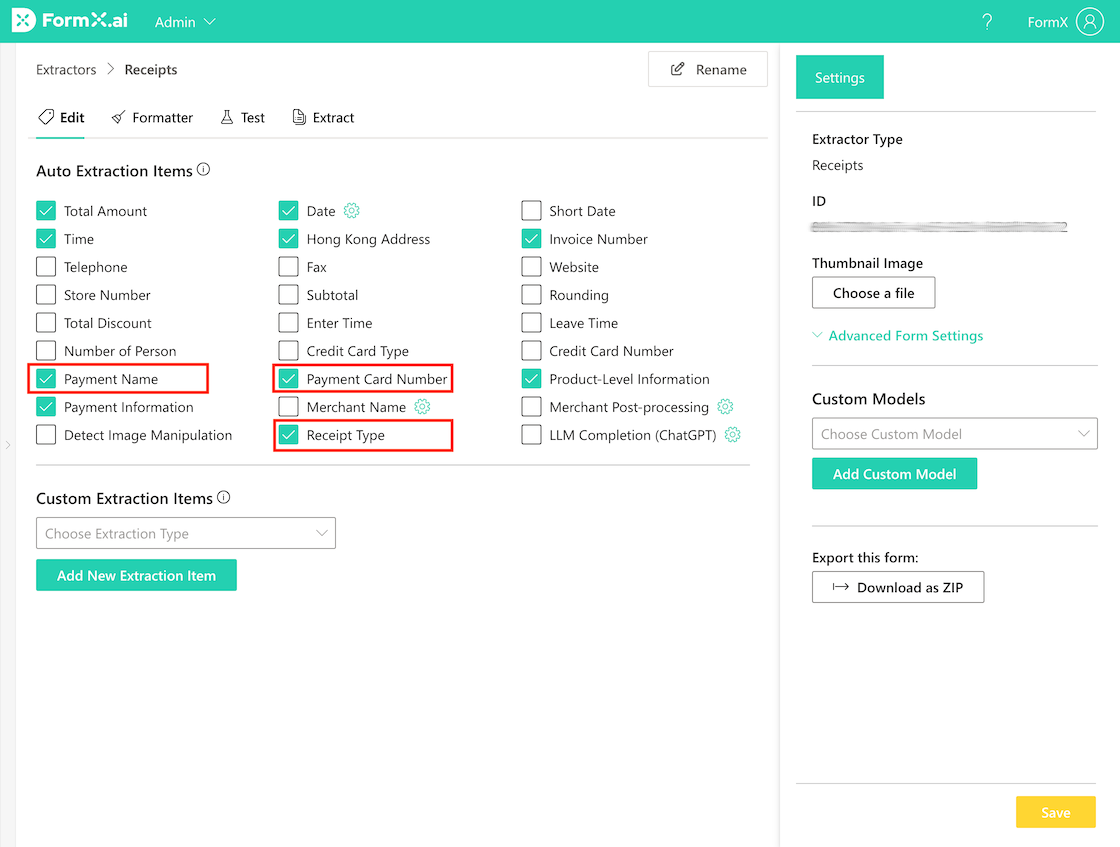
To auto-extract more info, tick the Receipt Type, Payment Name, and Payment Card Number checkboxes, as shown below, when configuring your Receipt Auto Extraction Items.
Desktop App Now Supports Multi-Page Document Extraction and Advanced Line Item Export Options
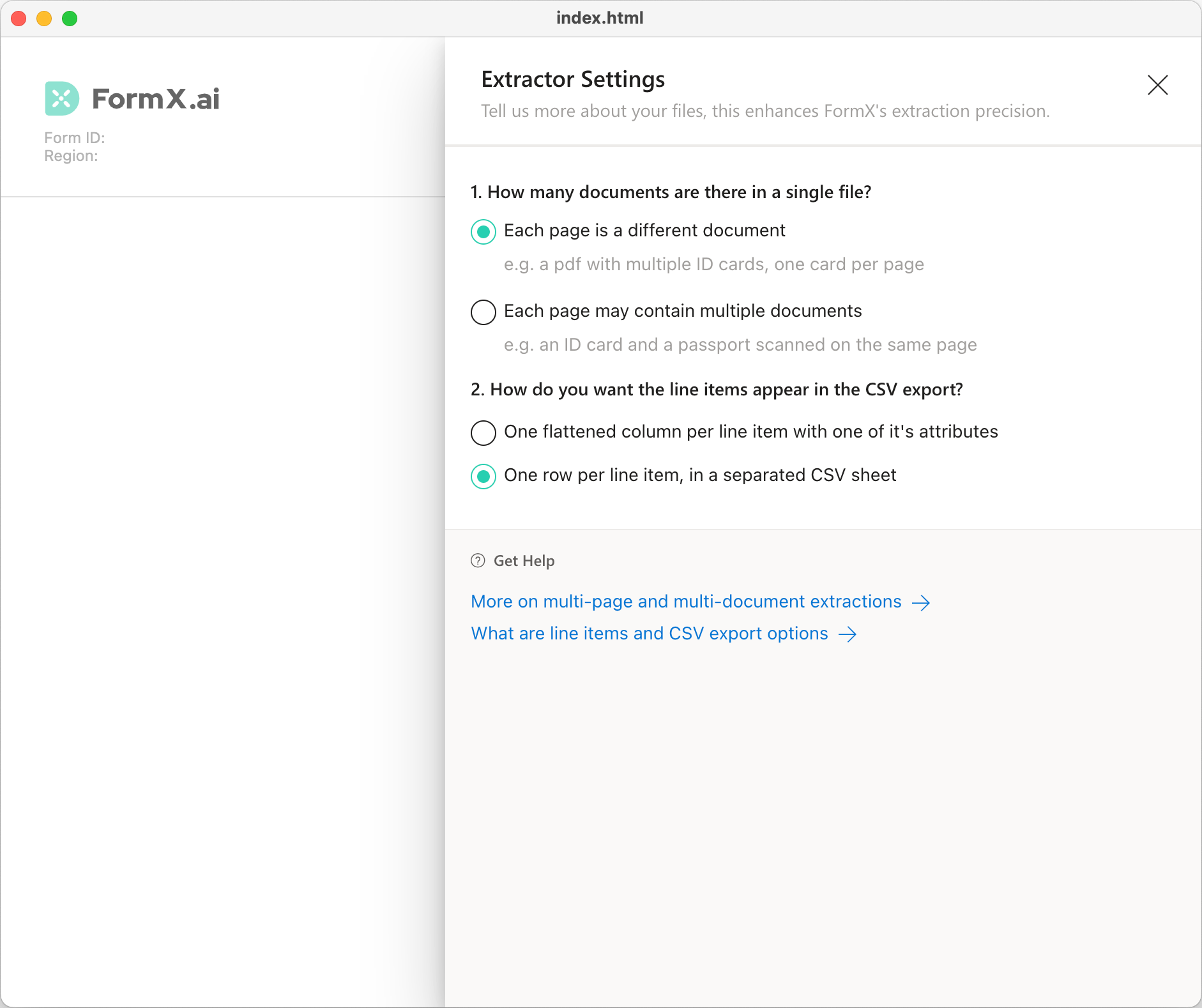
After entering your FormX and Access token, you can now change the settings to specify two things on the desktop app now.
First is to tell the Extractor whether each page of the file contains a single document or multiplle documents.
Second is to choose how you want the line items to appear in the CSV.
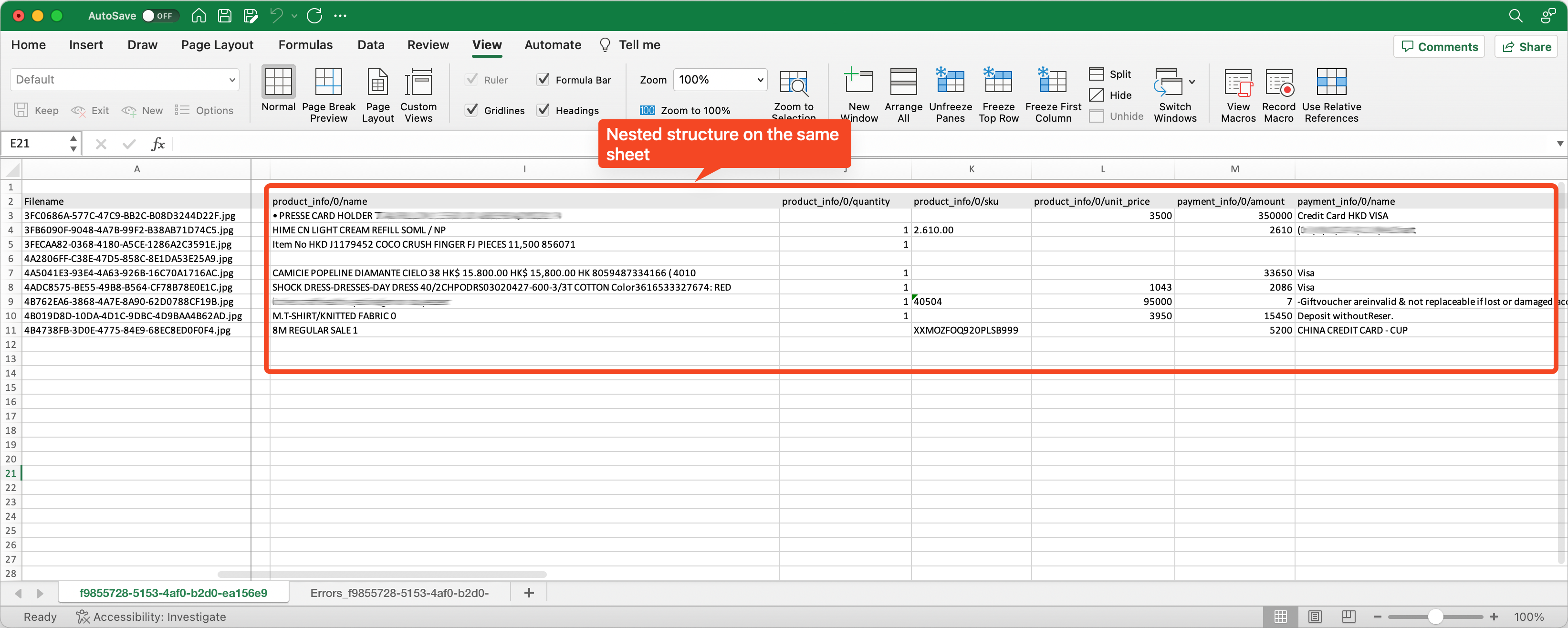
The default option is to show the nested structure as one flattened column per line item with one of its attritbute and all the line items will be shown in the same tab.
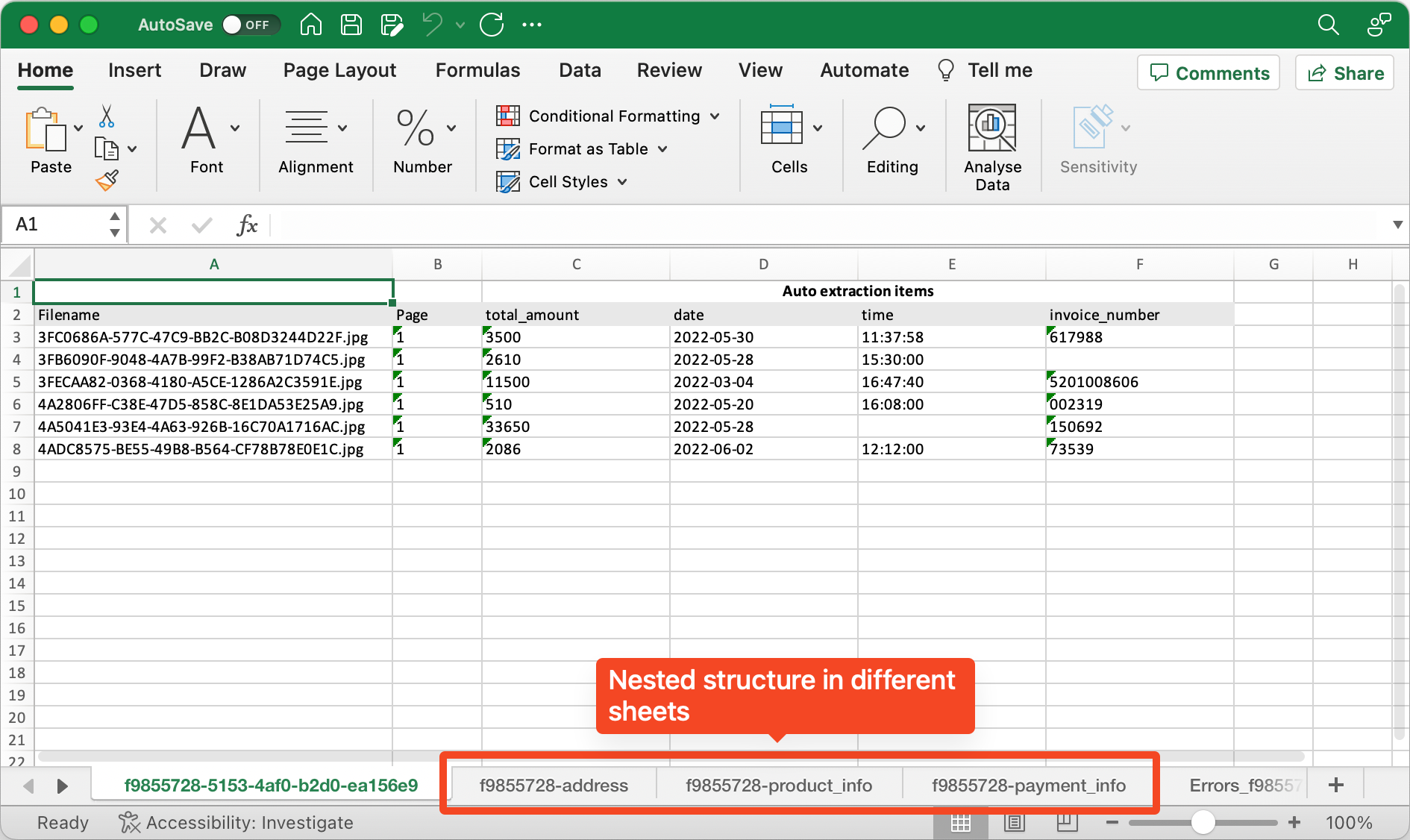
The second option, on the other hand, will separate the line items in different sheets.
Start your free trial or contact us to learn more about how your business can benefit from incorporating FormX into various internal or external processes to create more value.
