What Is Intelligent Document Processing: A Complete Guide
Intelligent Document Processing leverages several AI technologies to automate data extraction from various documents. Learn more

Data serves as the backbone of decision-making across industries, underpinning the very essence of informed choices. Having accurate data at your fingertips means businesses can create evidence-based strategies, understand customers to target better, and improve overall ROI. However, most data sources are unstructured, and a formidable challenge lies in the scanning and extraction of meaningful data from such massive sources. That’s where intelligent document processing comes in!
IDP utilizes artificial intelligence and machine learning to simplify the intricate task of extracting, processing, and organizing data from various unstructured documents. Want to know more about intelligent document processing and how it works? Let’s dive in!
The amount of data that’s being generated daily is huge - but 90% of this data is unstructured, making it hard for you to get hands-on, relevant, and helpful material. IDP comes as a savior in this situation! Employing a combination of artificial intelligence, machine learning, and natural language processing techniques, it automates data extraction, understanding, and processing from unstructured data sources.
IDP systems can accurately capture and categorize information, extract critical data points, and even interpret the context within documents. This means you can now get excess information from data sources like PDFs, emails, invoices, etc. While many people confuse OCR with IDP, remember they are different things. IDP incorporates OCR but is made to overcome the limitations of Optical Character Recognition.
Here, you’ll get an overview of the working of intelligent document processing and the technologies behind it:
Optical Character Recognition is a foundational technology within IDP, converting printed or handwritten text within documents into machine-readable text. OCR algorithms analyze the images of characters within documents, accurately identifying and translating them into digital text. These algorithms employ sophisticated techniques to recognize characters, irrespective of variations in fonts, sizes, or styles.
Natural Language Processing is a pivotal component of IDP, focused on comprehending and processing human language in a manner that computers can interpret and manipulate. Here are the techniques NLP makes use of in intelligent document processing:
- Named Entity Recognition (NER): Identifying entities like names, dates, and locations within documents.
- Sentiment Analysis: Determining the emotional tone or sentiment expressed in the text.
- Text Classification: Categorizing documents or text into predefined categories.
- Translating Languages: Translating text from one language to another.
Machine Learning (ML) is at the heart of Intelligent Document Processing (IDP), serving as the driving force behind its capabilities. In IDP, ML uses two significant techniques - Supervised and Unsupervised ML. The former equips IDP systems with the ability to accurately extract specific data from documents by training on labeled datasets. This streamlines tasks such as invoice data extraction and document classification.
Conversely, Unsupervised Learning within IDP brings forth the power to discern latent patterns and relationships within unstructured documents. This dual application of Supervised and Unsupervised Learning within IDP dramatically contributes to its versatility.
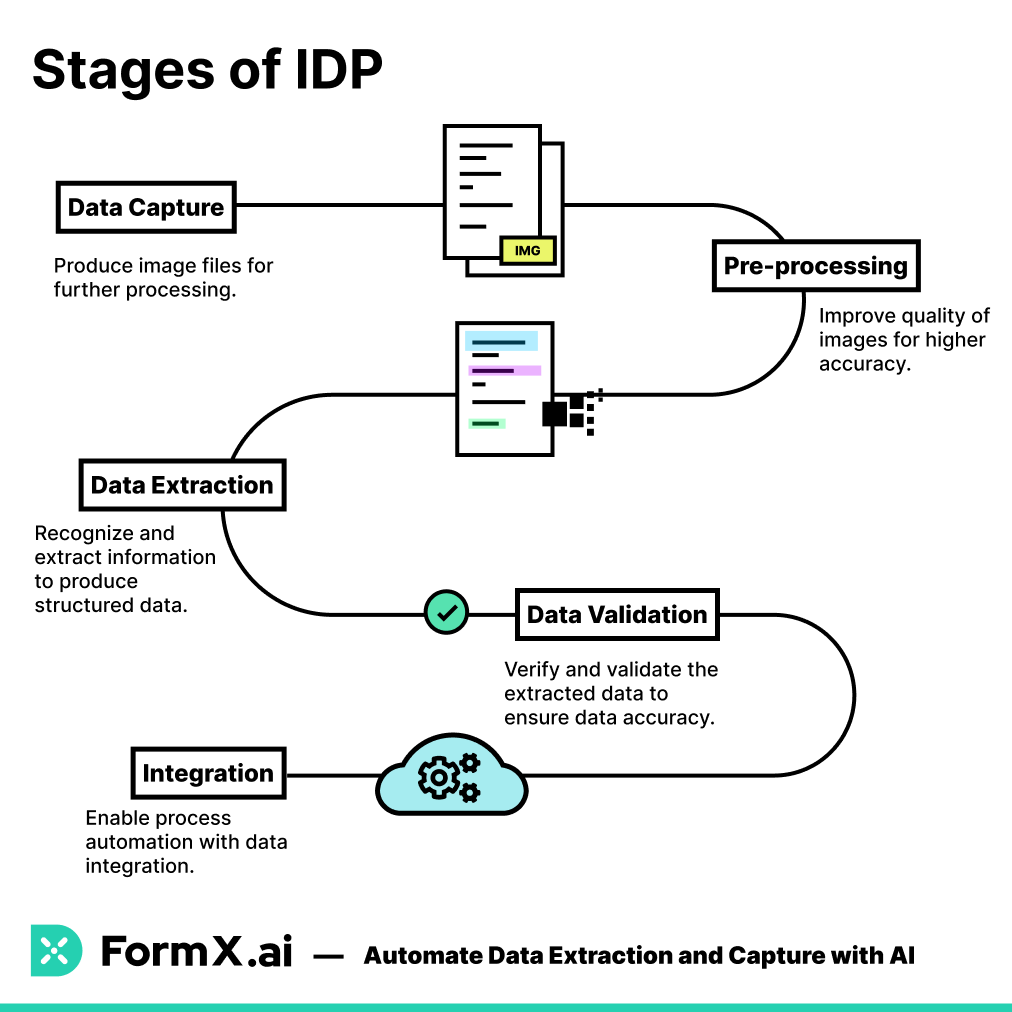
Here’s the step-by-step guide on the workflow of IDP:
Step 1: Image Pre-Processing
The first pivotal step in IDP is image pre-processing, where the images are optimized in order to maximize the accuracy of data extraction. Some techniques of image pre-processing include:
- Binarization : It’s the initial transformation applied to document images. It concerts them from colored or grayscale representations into a binary format. Pixels are shown as either black (pixel value = 0) or white (pixel value = 256), with the primary objective to create a stark contrast between the text characters (depicted as black pixels) and the background (depicted as white pixels).
- Deskewing : The scanned image may be horizontally aligned, which isn’t suitable for OCR. Deskewing rectifies these skewed angles, ensuring the text and content are properly aligned for accurate processing.
- Noise Removal : Noisy artifacts like speckles or artifacts can degrade the quality of scanned documents. Noise removal techniques are applied to eliminate these imperfections, resulting in cleaner images that are easier to process.
Step 2: Data or Document Classification
Following the document processing, data classification comes into play. This phase categorizes documents based on their content, format, or purpose. It helps you find whether the data is structured or unstructured and the type of document like pdf, jpg, etc.
Classification ensures each document is routed to the appropriate processing pipeline, allowing for tailored data extraction and validation procedures. For instance, invoices are classified differently from contracts, guiding the system to apply the relevant extraction rules.
Step 3: Data Extraction
With documents categorized, the core data or information extraction process commences. The following are some techniques or approaches that might come into play in this step:
- OCR (Optical Character Recognition) : OCR technology recognizes and converts printed or handwritten text within documents into machine-readable text. This step transforms the scanned images into digital text, enabling further analysis.
- Rule-Based Extraction : In this approach, predefined rules and patterns are established to extract specific data points from documents. For instance, rules can be created to identify and extract data from documents with fixed formats like ID cards, passports, etc.
- Learning-Based Approach : Machine learning models are utilized to learn from labeled examples of documents. These models can generalize from the training data to automatically extract data from new, similar documents. For instance, an IDP system trained on a dataset of invoices can learn to extract key invoice details without explicit rule-setting.
Step 4: Data Validation
Once data is extracted, it undergoes a critical validation phase. Validation rules and checks are applied to verify the accuracy and integrity of the extracted information. This may involve cross-referencing extracted data against existing databases or predefined standards. All this helps you stay assured that the data extracted from documents aligns with expected values and formats.
Step 5: Human Review
The final safeguard in the IDP process is human review. Documents that require human verification or correction are flagged and presented to human operators for meticulous review. This human intervention serves as the ultimate quality control measure and the feedbacks can help the machine learning models to improve accuracy in the future.
Experts get to address exceptions, discrepancies, or nuanced document elements that automated processes may not handle with complete accuracy. It ensures that the processed data meets the highest standards of accuracy and reliability.
Some of the advantages of intelligent document processing are:
Reduces Human Error
Human operators doing manual data entry are susceptible to fatigue and oversight, which leads to inaccuracies in data entry and document classification. You may not believe this; even the most forgiving statistics in data entry work show an average human error rate of 1%.
IDP, on the other hand, operates tirelessly and consistently. Adhering to predefined rules and machine learning models significantly minimizes the risk of errors.
It automates tasks like data extraction and validation, ensuring that your organization maintains high data accuracy. This is essential for informed decision-making and compliance with regulatory standards.
Boosts Efficiency
Manual data entry becomes a thing of the past, freeing your valuable human resources to focus on more strategic and complex tasks. IDP’s efficiency-boosting capabilities are transformative for your organization. Especially when dealing with substantial document volumes.
Automated or intelligent document processing speeds up data extraction from unstructured sources and streamlines document routing and organization through classification. All this helps your organization to focus on other intensive tasks, increasing overall efficiency.
Saves Money
IDP proves to be a cost-effective solution that results in substantial savings for your organization. By automating document processing, IDP reduces the need for extensive manual labor, significantly reducing labor costs. Furthermore, eliminating errors and inefficiencies translates into cost savings, as you can avoid costly mistakes and rework.
Here are three prominent IDP use cases:
Invoice Processing
Intelligent document processing is widely employed in automating invoice processing workflows. It can extract key information such as invoice numbers, dates, line items, and totals from various invoice formats. This streamlines accounts payable processes, reduces manual data entry, and accelerates payment cycles while minimizing errors.
Contract Management
IDP is also instrumental in contract management by extracting essential data from contracts, such as terms and conditions, obligations, and deadlines. It helps organizations stay compliant, track contractual commitments, and manage their contract portfolios efficiently.
Customer Onboarding
In industries like finance and insurance, IDP simplifies customer onboarding processes. It can swiftly extract and verify customer information from a range of documents. These vary from IDs and utility bills to application forms, expediting onboarding and enhancing regulatory compliance.
Here are the challenges of intelligent document processing:
Low Document Quality
IDP systems often encounter documents of varying quality, including those with faded text, smudges, or poor scanning quality. Such low-quality documents can pose challenges for accurate text recognition and data extraction, potentially leading to errors in the extracted information. IDP solutions must incorporate robust pre-processing techniques to effectively handle and enhance document quality.
Various Types of Documents
Organizations deal with many document types, from invoices and contracts to handwritten notes and forms. Each document type may require different extraction methods, rules, and post-processing. Managing the diversity of document formats and content structures can be complex, demanding versatile IDP systems that can adapt to handle various document categories.
Language Barriers
Language diversity and multilingual documents present a significant challenge for IDP solutions, particularly in global organizations. Dealing with documents in different languages requires robust multilingual OCR capabilities and language understanding tools. A competent IDP solution must have this.
FormX.ai offers an IDP solution that resolves all of these challenges. It translates a variety of documents in different languages and features powerful processing techniques that make it easy to scan damages, unaligned images, documents, and texts.
The future of Intelligent Document Processing (IDP) promises a transformative landscape for businesses and organizations. It will continue to drive automation to new heights, relieving you of repetitive tasks like data entry and document sorting and allowing you to focus on more strategic endeavors.
Advancements in artificial intelligence will grant IDP systems a deeper understanding of context within documents, unlocking richer insights. This heightened accuracy will reduce errors and enhance trust in the data processed by IDP. Customization will be a central theme, with solutions becoming more adaptable to unique document requirements and seamlessly integrated into existing workflows.
Multilingual support will break language barriers, making IDP a global asset. Furthermore, as regulations evolve, IDP will be pivotal in assisting organizations with intricate compliance needs, contributing to cost savings. As per Markets and Markets, the intelligent document processing market is expected to generate $5.2 billion in revenue by 2027.
If you are looking for a reliable, intelligent document processing solution, FormX is the right choice:
FormX is a top-tier intelligent document processing software engineered to excel in document data management. Its prowess in IDP lies in its feature-rich design tailored for optimal efficiency. FormX’s pre-configured data extraction models set the stage for precise and rapid data extraction, covering an array of document types from shopping receipts to official licenses. This feature becomes particularly invaluable in the context of IDP, where the accurate extraction of data is paramount. Moreover, as FormX leverages large language models like GPT-3.5 or GPT-4, training a new data extraction model requires as little as one sample image and just a few minutes.
With FormX, users can effortlessly obtain vital data with just a few clicks, streamlining data-intensive processes with unwavering accuracy. Furthermore, FormX’s API-based data extraction exemplifies its commitment to adaptability and seamless integration. The results are conveniently returned in well-structured JSON format, ensuring compatibility with various software environments. This developer-friendly approach aligns seamlessly with the ethos of IDP, facilitating effortless integration into existing workflows. The results can also be returned in other structured formats like CSV or XML that can be directly imported into other applications.
FormX’s user-friendly web portal adds to its allure, offering intuitive instructions catering to novices and experts. Users can confidently manage parsing configurations, test data extraction processes, and access integration materials, all within a single platform. FormX is an indispensable tool for organizations that want to effortlessly harness the power of document data for informed decision-making and operational excellence.
Intelligent Document Processing (IDP) has emerged as a transformative force in document management and data extraction. Its integration of technologies like OCR, NLP, machine learning, and large language model has revolutionized how you handle unstructured data. From reducing human errors to boosting efficiency and saving costs, IDP has demonstrated its worth across various industries.
Contact us if you are interested in learning how FormX can be of help to your business or sign up for a free trial to see how simple data extraction can be.
Latest articles



